



Pada komputer paralel, arsitektur memori diklasifikasikan menjadi tiga kategori antara lain:
1. Shared Memory
Pada arsitektur jenis ini, prosesor dapat mengakses semua memori sebagai space alamat global. Shared momory dibagi menjadi dua kelas yaitu UMA (Uniform Memory Access) dan NUMA (Non-Uniform Memory Access).
2. Distributed Memory
Arsitektur jenis ini prosesornya mempunyai memori lokal sendiri, sehingga inter-prosesor memori membutuhkan networking.
3. Hybrid distributed-shared memory
Arsitektur ini menggabungkan tipe shared dan distributed.
UMA sendiri merupakan kelas dari shared memory dengan karakteristik semua prosesor dapat mengakses semua memori sebagai ruang alamat global. Multiprosesor pada jenis ini dapat beroperasi secara independen namun dapat saling berbagi memori. Karena hal tersebut membawa dampak perubahan di lokasi memori oleh satu prosesor dapat dilihat oleh prosesor yang lainnya (yang terhubung ke memori yang sama). Prosesor pada model UMA ini, mempunyai akses dan waktu akses yang sama ke mori di setiap prosesornya. Cache coheren menjadi problem utama pada model ini dikarenakan jika suatu prosesor update suatu lokasi di memori, semua prosesor mengetahui update tersebut, sehingga koherensi dilakukan di level hardware (lihat Gambar 1).

Gambar 1. Arsitektur UMA
NUMA memiliki karakteristik prosesor memiliki bank alamat memori sendiri, sehingga prosesor dapat mengakses memori lokal dengan cepat, sedangkan untuk memori remote lebih lambat. Pengaksesan pada data lokal dapat meningkatkan throughput memori pada jenis arsitektur ini. Sseringkali model ini digunakan untuk menghubungkan secara fisik dua atau lebih SMP, satu SMP dapat mengakses memori secara langsung ke SMP yang lainnya. Berbeda dengan tipe UMA, pada NUMA tidak semua prosesor mempunyai waktu akses yang sama ke memori. NUMA memiliki kelemahan yaitu akses memori lewat bus interconnect lebih lambat karena berada diluar jalur lokalnya (lihat Gambar 2).
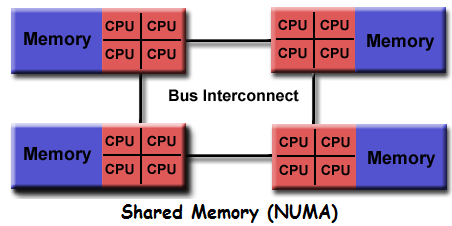
Gambar 2. Arsitektur NUMA
Bila disimpulkan secara keseluruhan dua tipe pada jenis Shared Memory bahwa space alamat memori global menyediakan perspektif pemrograman user-friendly ke memori, selain itu sharing data antar task cepat dan uniform karena dekatnya memori ke CPU. Namun apabila dilihat dari kelemahan pada bangunan arsitektur ini adalah tidak scalable artinya menambah CPU dapat meningkatkan trafik di jalur shared memory--CPU. Kelemahan yang lainnya adalah programmer bertanggungjawab untuk sinkronisasi yang memastikan akses yang tepat ke memori global. Tentunya hal ini akan berdampak semakin kompleks dan mahal seiring semakin bertambahnya jumlah prosesor.
Pada Jenis yang kedua pada komputer paralel adalah distributed memory dimana tiap prosesor mempunyai memori lokal sendiri, sehingga prosesor dapat beroperasi secara independen. Perubahan yang terjadi pada sisi lokal memori tidak akan membawa efek ke memori lainnya. Pada arsitektur ini, jika memerlukan interprocessor, tugas programmer secara eksplisit mendefinisikan bagaimana dan kapan data akan dikomunikasikan (lihat Gambar 3).

Gambar 3. Distributed Memory Architecture
Kelebihan yang didapatkan dari jenis distributed ini adalah scalable jumlah prosesor dan ukuran memori dapat ditingkatkan. Tiap prosesornya dapat mengakses memorinya tanpa interferensi dan overhead, seperti dikoheren cache. Pada jenis ini menjadi cost effecitve apabila menggunakan PC komoditas, off the self processor. Tetapi kelemahan yang ditemukan pada arsitektur ini adalah tugas programmer akan semakin kompleks terkait dengan detail komunikasi datanya, selain itu mapping data struktur berbasis memori global bisa jadi susah.
Jenis yang ketiga adalah Hybrid Memory yang terdiri dari arsitektur memori shared dan distributed. Komponen memori shared biasanya mesin SMP koheren (prosesor di mesin SMP mempunyai akses global ke memori mesin tersebut), sedangkan komponen distributed adalah jaringan SMP multiple (SMP hanya tahu memorinya saja). Komunikasi jaringan diperlukan untuk memindahkan data dari satu SMP ke lainnya.






